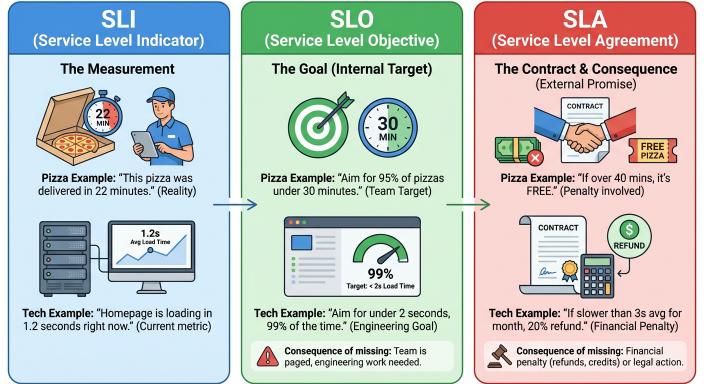
I often mix up these terms SLI, SLO, and SLA, so here’s a simple way to understand them.
1️⃣ SLI – Service Level Indicator
What we measure: An SLI is just a number that tells us how the system is doing.
Examples:
-
Response time of an API
-
Percentage of successful requests
-
Uptime of a service
👉 Example:
“Out of 1,000 requests, 998 were successful.”
That’s an SLI.
2️⃣ SLO –Service Level Objective
What we aim for (internally): An SLO is a target we set for an SLI. Engineering teams use it to guide reliability.
👉 Example:
“Our API should be available 99.9% per month.”
This means:
-
A small amount of downtime is acceptable
-
We track it and try to stay within limits
SLOs are not legal promises — they are internal goals.
3️⃣ SLA – Service Level Agreement
What we promise to customers: An SLA is a contractual commitment. If we don’t meet it, there may be refunds or service credits.
👉 Example:
“We guarantee 99.5% availability per calendar month.”
This is why SLAs are usually less strict than SLOs — they carry risk.
🔁 How they work together
-
SLI → what we measure
-
SLO → what we target
-
SLA → what we promise
Example:
-
SLI: actual uptime = 99.93%
-
SLO: target uptime = 99.9%
-
SLA: promised uptime = 99.5%
✅ Everyone is happy.
Final thought 💡
You can’t have a meaningful SLA without:
-
Clear SLIs
-
Proper monitoring
-
Realistic SLOs
If it’s not measurable, it’s not enforceable.